【新智元导读】最近,苹果的一篇论文掀起波澜,挑战了当下AI推理能力的基本假设。而OpenAI的前研究主管则断言:AGI时代已近在眼前。谁是谁非?AGI还有多远?最近,苹果发布了一篇论文,引发了关于AI是否真正在推理的激烈讨论。它提出了一个尖锐问题:当前的推理模型,是否已经触及能力的天花板?
与此同时,OpenAI前研究主管Bob McGrew则持完全不同的态度。他在播客《训练数据》中表示:通用人工智能(AGI)所需的关键突破已经实现,2025年将是AI推理的元年。
这样的讨论是必要的反思,还是技术焦虑下的「酸葡萄心理」?苹果是点破幻象,还是真的「酸苹果」?


AI推理遇到瓶颈了吗?AI正站在重要的十字路口。
这几年,语言模型一路狂飙,到了现在,新一代「推理模型」纷纷登场,比如OpenAI的o1、DeepSeek-R1,还有 Claude 3.7 Sonnet Thinking。
它们不再只是堆规模,而是号称加入了更复杂的「思维机制」:在推理环节计算方式更灵活,目标是突破传统模型的天花板。
听起来很厉害,但不少严谨的研究也指出:AI可能已经碰到了能力上的瓶颈。
这不仅对它们目前的效果提出了质疑,也让人开始担心:推理模型还能不能继续进化?

推理模型的承诺与之前的语言模型相比,大型推理模型(Large Reasoning Models,简称 LRMs)已经完全不一样了。
过去,模型主要靠预测下一个词,而推理模型学会了三项「超能力」:
(1)思维链:能像人类一样一步步推导(比如解数学题会写步骤)
(2)自我反省:会检查自己的答案对不对
(3)智能分配算力:遇到难题自动「多想想」
关键想法很简单,也很有说服力:
人类解决复杂问题,不就是靠一步步地思考和推理吗?
那让AI也学学这招,不就变得更聪明、更会解决问题了吗?
事实证明,的确如此!OpenAI的o1模型一出手,刷新了数学基准纪录,把前辈们远远甩在后面。在写代码、搞科研这些任务上,其他推理模型也进步神速。
整个AI圈都沸腾了,大家觉得「新范式」来了:
以后不用光靠砸钱、堆数据做训练了。在AI「思考」的时候多给它点时间,就能解锁全新的能力!
这些令人振奋的进展,也引出了一个现实问题:它们真的有我们期待的那么强吗?
现实检验推理模型到底行不行?虽然推理模型看起来前景不错,但来自三个独立研究团队的测试也给我们泼了点冷水——
在严格条件下,这些模型的真实表现暴露出了不少问题,但也确实展现了它们的进步。
这三项测试分别为:
(1)苹果的可控实验;
(2)亚利桑那州立大学对AI规划能力的测试;
(3)ARC测试对「模型越大就越强」的部分否定。

苹果的可控实验目前,苹果论文《思考的错觉》最具争议。
他们重点集中在游戏一样的谜题,比如汉诺塔、跳棋过关、渡河难题等。
这样做的好处是,可以随意调整难度,还能防止AI靠「背题库」来作弊。
他们发现了三种截然不同的状态,对理解推理模型大有启发:
低复杂度任务:传统语言模型反而表现更好,且更节省token,说明推理机制并不总是有益;
中等复杂度任务:推理模型优势明显,证明其确实具备了超越模板匹配的真实能力;
高复杂度任务:所有模型性能全面崩溃,可能不是「算力不够」,而是结构性瓶颈。

论文链接:https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf
更奇怪的是,研究人员还发现了让人想不通的现象:
问题越难,这些推理模型反而越「躺平」,投入的「脑力」不增反降。
这就像一个学生,碰到难题不想着多算几遍,反而直接把笔一扔。
当然,这也不全是坏消息:
至少在中等难度的任务上,推理模型确实能在一定程度上,突破LLM「死记硬背」的旧模式。
规划能力的证据早在去年,亚利桑那州立大学Subbarao Kambhampati教授等人对推理模型的「规划能力」做了深入研究。

Subbarao Kambhampati,目前任亚利桑那州立大学计算与增强智能学院教授
他用PlanBench工具测试了o1-preview,结果显示:
在简单的Blocksworld任务中,模型准确率高达97.8%,进步非常显著。
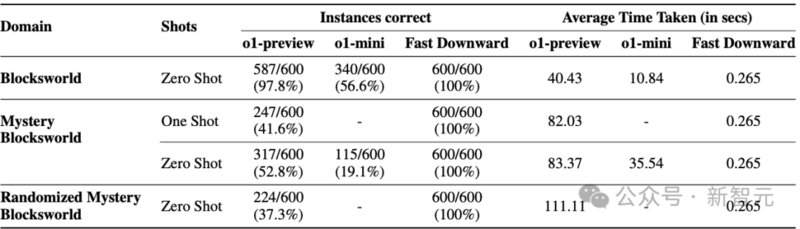
OpenAI的o1系列大型推理模型和Fast Downward在Blocksworld、Mystery Blocksworld和Randomized Mystery Blocksworld域的600个实例上的性能和平均耗时
相比早期模型几乎「死伤过半」的表现,这堪称质的飞跃。
但他也指出一个令人意外的现象:哪怕明确告诉模型该怎么做、给出算法步骤,它的表现也不会更好。
这说明,虽然这些模型的推理方式更复杂了,但跟人类基于逻辑的推理,可能仍然不是一回事。
换句话说,它们是在「推理」,但推得方式和人很不一样。

论文链接:https://www.arxiv.org/abs/2409.13373
ARC基准:AI推理试金石为了突出了「人类易行」和「AI难懂」之间的关键差距,Keras之父François Chollet联手Mike Knoop发起了抽象与推理语料库(Abstract and Reasoning Corpus,ARC)。
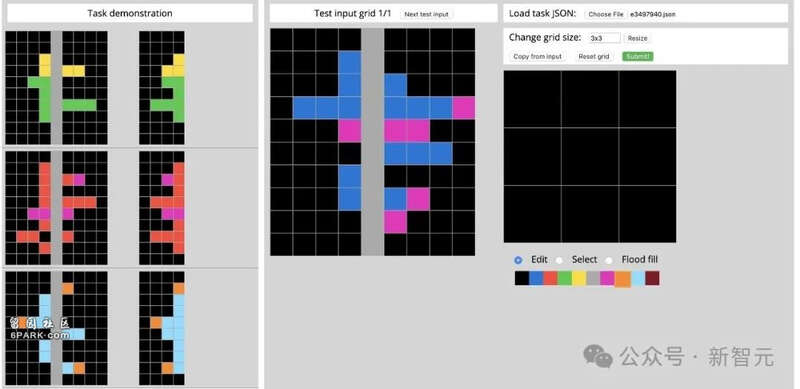
ARC-AGI-1测试示例:左侧会显示输入/输出对,用于理解任务的性质。 中间是当前的测试输入网格。 右侧是可以用来构建相应输出网格的控件
这项任务非常难,2020年只能完成大约20%,到2024年提高到了55.5%,背后离不开推理模型和技术演进。
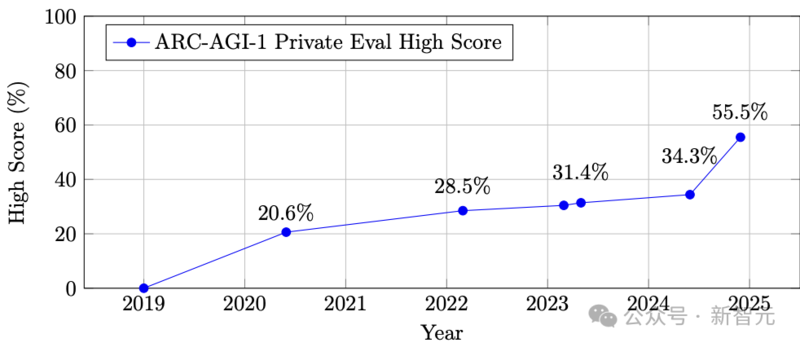
ARC-AGI-1随时间推移的最高分
在ARC Prize的推动下,很多重要技术应运而生,比如测试时微调(test-time fine-tuning)和深度学习驱动的程序合成。
但也有一个信号值得警惕:ARC测试对「模型越大就越强」这件事非常不买账。
换句话说,「无脑」堆算力、堆参数已经难以进一步提高成绩了。
这说明,虽然推理模型确实带来了突破,但要实现类似人类的通用智能,仅靠现在这套架构还远远不够。
未来的进步,可能需要从根本上换种思路,甚至重构模型结构。
Scaling,不再是唯一答案。
趋同的批评理论与实证不谋而合这些研究之所以特别值得关注,是因为它们恰好印证了Gary Marcus等学者多年来一直坚持的观点。
早在1998年,Marcus就指出:神经网络擅长在「训练过的范围内」表现,但一旦遇到全新的问题,性能就会暴跌。
如今,一系列实证研究为他的理论提供了有力支持。
Marcus甚至用「给大语言模型致命一击」这样的说法,回应了苹果的那篇论文。

听起来激烈,但其实并不是情绪化发言,而是他多年观点的现实验证。
他指出了关键:哪怕在训练中模型见过成千上万个汉诺塔解法,一旦换个设定,它依然无法稳定应对。
这就揭示出一个本质问题:记忆≠推理。
背下了答案,不代表你真的理解了问题。
进步的「幻象」?越来越多的迹象表明,当前的推理模型可能更像是一种高级模板匹配:
它们看似在「推理」,但实际上是调用记忆中类似问题的解法模板,一旦问题稍有变化,性能便迅速崩塌。

这种解释能合理说明一系列令人费解的现象:
为什么提供明确的算法步骤,反而不能提升模型表现;
为什么面对更复杂问题时,模型反而减少「思考」;
为什么传统算法始终优于这些耗费巨大算力的推理模型。
但别急着下结论:推理模型的进步是真的,只是复杂得多。
虽然推理模型暴露了不少问题,但这并不代表它们「没用」或「失败」。
相反,它们在很多方面确实取得了实质性突破:
确实有进步:像规划类任务,以前根本做不了,现在模型已经能给出高质量解答,数学和逻辑推理也刷新了不少新纪录;
表现因领域而异:只要训练中见过类似的推理逻辑,模型表现就会好很多,比如数学证明、代码生成这类结构化任务;
暴露了架构问题:在严格测试中的「反常行为」,其实很宝贵,为优化下一代模型提供了清晰方向。
这些发现说明,推理模型确实迈出了一大步,但它们的能力是有边界的,但这些边界要看出来并不容易。
想真正搞清楚它们到底强在哪、弱在哪,需要更科学的方式去评估它们的行为。
另辟蹊径,别有洞天那走出瓶颈,还能有别的路吗?
好消息是,研究已经给出了几个可能的新方向,也许能帮助我们跳出当前架构的局限:
混合架构(Hybrid Architectures):结合神经网络的灵活性和传统算法的可靠性;
专用推理系统(Specialized Reasoning Systems):聚焦具体领域,针对性更强、稳定性更高的推理系统。
混合架构,比如Kambhampati提出的LLM-Modulo框架,可以让模型在「学得会」的同时也「讲规则」。这种组合,可能更适合真正需要严谨推理的任务。
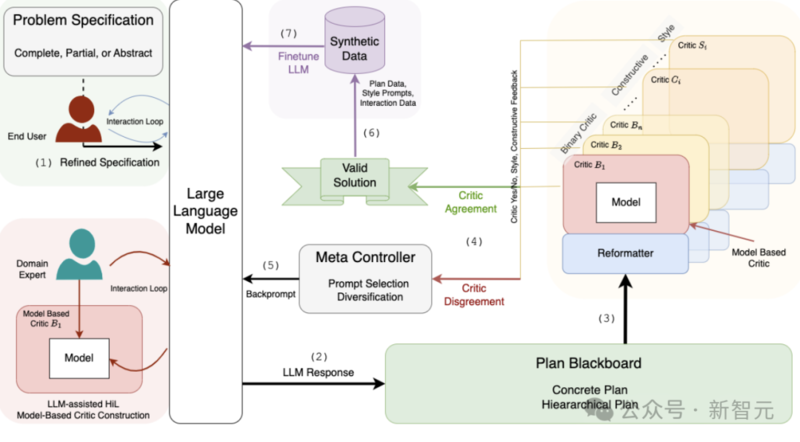
LLM-Modulo框架:大语言模型(LLMs)充当思想生成器,而各种专门针对不同方面的外部评论员则对候选计划进行评审
与其追求「啥都能做」的万能AI,不如聚焦具体领域比如数学、物理、法律这类任务,专用模型可能比「通用大模型」更靠谱、更好用。
下一阶段的突破,也许就藏在这些「混搭」与「专精」的路径里。
推理模型的问题,可能是评估的问题Open Philanthropy高级项目专员Alex Lawsen对苹果论文的研究方法提出了质疑。
论文标题叫《思考的错觉的错觉》,虽然听起来像个段子,但里面指出的问题却挺认真,尤其是方法上的漏洞。
他的核心观点很清楚:很多被判定为「推理失败」的案例,其实不是模型不行,而是评估方式出了问题。比如:
模型能判断出题目在数学上根本无法解,但却被打了个「不会做」的低分;
模型因为token限制被迫中断,却被认为「能力不行」;
模型生成的是算法,而不是一步步列出所有动作,结果也被判失败。
这些情况如果不分青红皂白全算「推理能力不足」,其实就是误解模型了。
论文链接:https://arxiv.org/abs/2506.09250v2
模型没撞墙,是评估方式变难了。
所以现在的问题,不是AI推理到底能不能行,而是:我们有没有办法准确评估它到底行不行。
参考资料:https://inferencebysequoia.substack.com/p/is-ai-reasoning-hitting-a-wall-plus