如果面前有两个AI助手:一个很聪明但经常不守规矩,另一个很听话但不太聪明,你会怎么选?
最近,上海人工智能实验室与香港中文大学的研究团队发布了论文《Scaling Reasoning, Losing Control: Evaluating Instruction Following in Large Reasoning Models》,通过一个全新的评测基准MathIF揭示:
大模型越擅长复杂推理,越容易忽略用户的指令要求,“聪明”和“听话”之间存在明显的矛盾。
这项工作的灵感,源自实际使用推理模型(如o3)过程中的一个意外发现:相比许多经过强化推理训练的大模型,GPT-4o在执行具体指令时反而更加“听话” 。也正是这种“越聪明、越不听话”的真实体验,让研究团队开始系统性地研究推理能力与指令跟随之间的关系。
这一研究也引来𝕏知名博主的转发:

研究揭示越擅长数学推理的模型反而越难完全遵守指令,同时分析了模型大小与服从性的非正相关现象,强调了推理能力与指令遵循之间的权衡。
MathIF:衡量推理模型“听话程度”的新基准
MathIF基准专门针对数学推理任务,考察AI模型是否严格遵循用户给出的指令要求。这些要求包括格式、语言、长度和特定关键词使用,均可通过程序自动验证。
MathIF由来自不同难度的数学题目组成,涵盖了从简单的数学问题(GSM8K)到复杂的数学竞赛题目(AIME)。每个题目都会附带具体而明确的指令,比如:“答案必须以一句中文完整作答,不能有多余解释。”
此外,MathIF还设计了单一指令、双重指令和三重指令的组合情形,以测试模型在不同约束复杂程度下的表现。模型不仅需要正确解题,还要严格遵守这些指令要求。
自动评分程序会精确检查答案是否符合每个具体的指令标准,分别以硬准确率(HAcc)和软准确率(SAcc)衡量模型的服从程度:HAcc 表示是否全部指令都被满足,而 SAcc 则反映每条指令的平均满足比例。

△图表1 MathIF 的指令类型越聪明越不听话?实验揭示“聪明”与“听话”的矛盾
研究团队使用MathIF评测了23个当前主流的大模型。这些模型包括不同的参数规模和训练方式,涵盖从数十亿到数百亿参数的各种类型。
实验结果令人意外:在数学推理能力表现越出色的模型,反而更难完全遵守用户给定的指令要求。即使是表现最佳的模型Qwen3-14B,也只能成功遵守一半的指令提示。
此外,模型的大小与其遵守指令的能力并不呈正相关,甚至有时会出现负相关——即更大的模型并不一定更守规矩。一些较小的模型反而更善于严格执行用户的指令。
指令遵循(instruction-following)与数学推理能力(mathematical reasoning)之间存在一种权衡关系(trade-off)。也就是说,当模型在推理能力上表现得更强时,它往往更容易忽略或违反用户的具体指令。
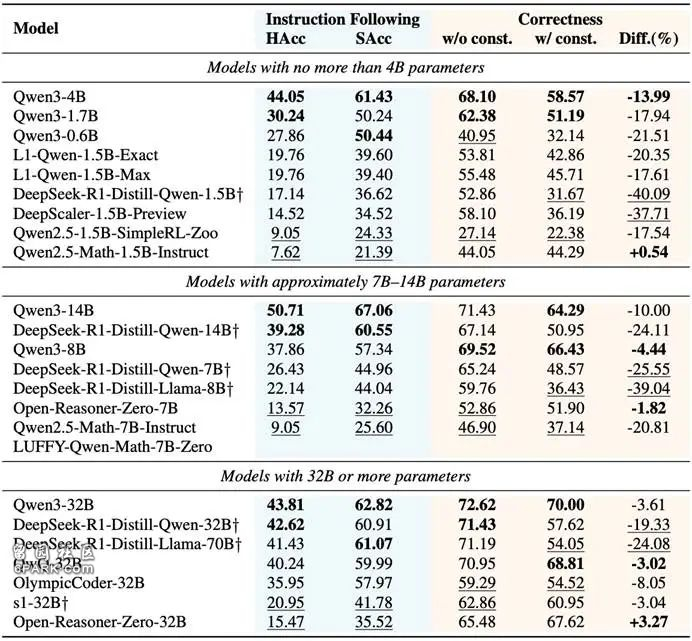
△图表2 23个大推理模型在MathIF上的表现
模型按服从性(HAcc + SAcc)表现从高到低排序。表中†符号表示该模型仅通过监督微调(SFT)训练,未使用推理导向的强化学习方法。粗体+下划线标记则分别代表各列指标中的前两名与后两名。
为什么聪明模型更“不听话”?
研究团队进一步分析了这个现象背后的原因:
原因一:推理导向的训练模式
研究发现,旨在强化模型推理能力的训练方式(如监督微调(SFT)和强化学习(RL)),虽然显著提升了模型的“智力”,却在一定程度上削弱了其对具体指令的敏感性。
这类模型往往更专注于如何准确解题,而容易忽视诸如格式、字数等细节要求。正如图3所示,无论是SFT还是RL,推理导向训练虽然提升了解题表现,却普遍导致模型在指令遵循能力(HAcc与SAcc)上的下降。
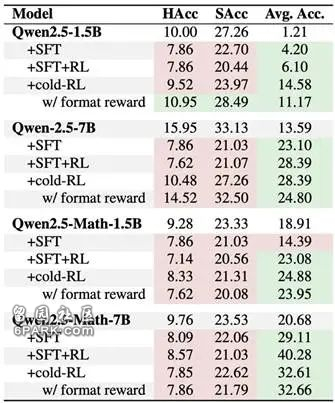
△图表3 推理导向训练策略的对比
其中Avg. Acc.表示在所有基准任务上的平均表现。绿色和红色背景分别表示相较于基础模型性能的提升和下降。
原因二:长推理链降低服从性
模型输出的推理过程越长(“链式思考”越复杂),越容易“忘记”指令要求。长段的复杂推理过程,容易让模型注意力分散,最后导致违背用户指令。如下图,将模型的推理结果按照长度进行分桶,推理长度越长,模型的指令遵循准确率越低。

△图表4 不同推理链长度区间下的HAcc和SAcc表现
长度分桶编号越大表示生成的推理链越长。
研究团队通过实验进一步验证了这一现象:当模型被引导生成更长的推理过程时,其遵循指令的准确率会明显下降。
具体做法是,在模型推理结束前人为添加“wait”等提示,迫使其继续延长思考过程,从而生成更长的推理链。如下图所示,“思考越多”,模型对指令的执行反而越不准确。
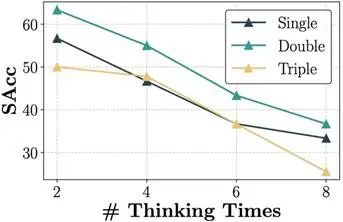
△图表5 模型指令跟随能力的变化趋势
此外,研究团队还通过在训练阶段控制模型的推理长度,进一步观察其指令跟随能力的变化。
具体而言,他们在强化学习(RL)的 rollout 阶段设置最大生成长度限制,超过该长度的回复将无法获得奖励,从而间接压缩模型的推理链长度。
从下图可以看出,限制推理长度有助于显著提升模型的指令遵循能力(HAcc和SAcc)。当最大长度控制在1k以内时,模型在服从性方面的表现甚至超过了原始基线模型。
然而,这种提升也带来了代价:模型的数学推理能力明显下降,表现出“听话”和“聪明”之间的权衡关系。
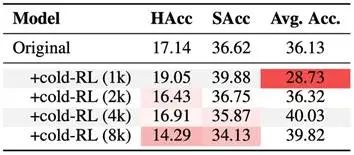
△图表6 RL训练中最大响应长度的影响
红色区域表示相较于基础模型(Original)性能下降,颜色越深表示下降幅度越大。
这些现象进一步印证了研究团队的结论:偏向生成更长推理链的推理导向训练,往往会在无意中削弱模型对指令的遵循能力,凸显了推理能力与指令服从性之间长期存在的权衡关系。
小技巧:让模型更“听话”的简单方法
研究者也尝试了一个简单的方法改善模型的“听话程度”:在模型推理结束后,输出答案之前,再次重复一遍指令要求。
结果显示,这种方法拉近了指令和回复的距离,确实有效提升了模型的指令遵守能力,但同时也稍微降低了模型回答问题的准确率。模型为了遵守规则,不得不牺牲一点自己的数学推理能力。

△图表7 通过在推理后重复指令提升指令遵循能力。
当前主流的推理导向训练方式,虽然显著提升了模型的解题能力,却不可避免地削弱了其对指令的遵循能力。AI的“聪明”与“听话”之间,正面临一场难以调和的矛盾。
未来,MathIF基准有望构建既能深入思考,又能严格守规矩的大模型。
论文地址:https://arxiv.org/pdf/2505.14810Github地址:https://github.com/TingchenFu/MathIF


